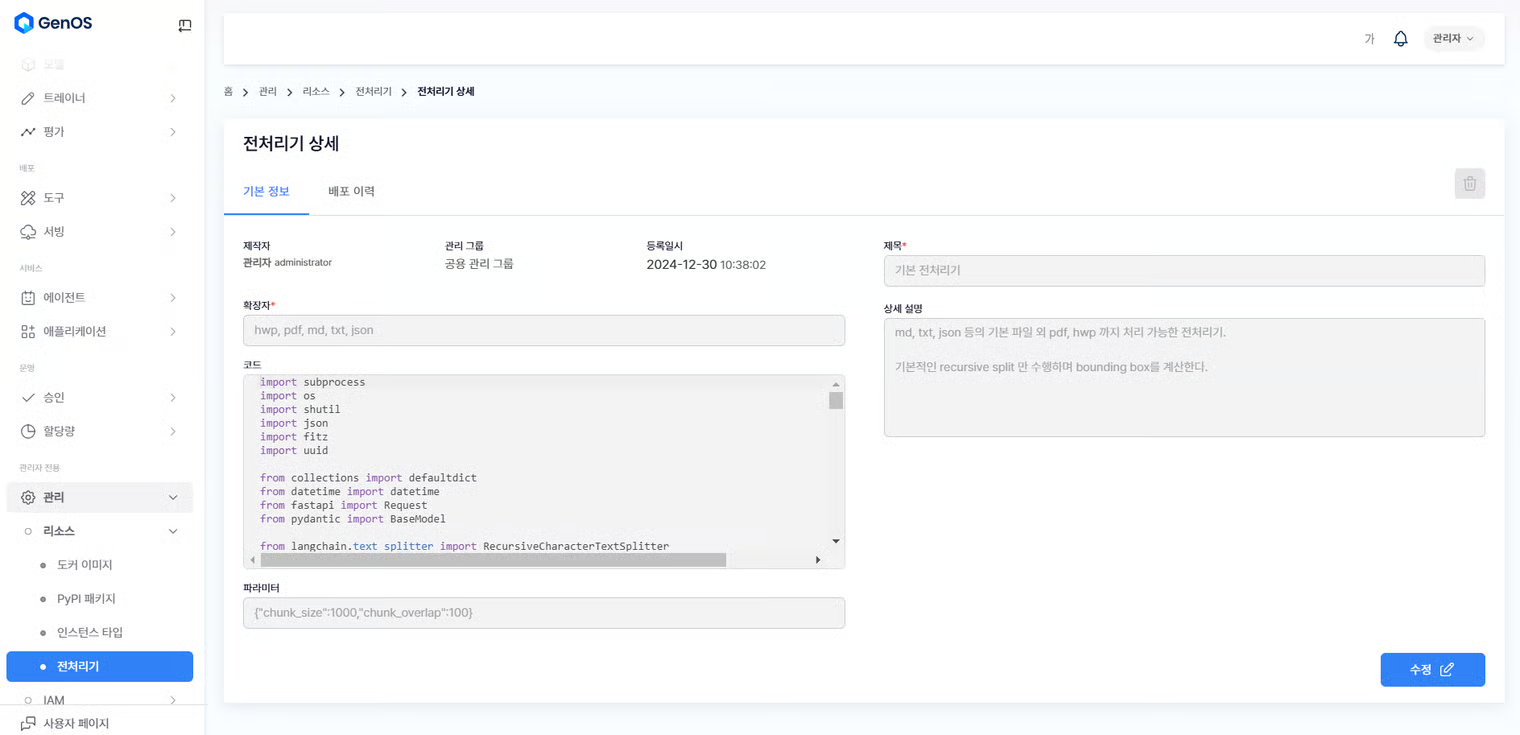
***
여기서는 Genos 적재용(외부) 지능형 문서 파서의 전처리 파이프라인 내 주요 구성 요소에 대한 코드 중심의 설명을 제공합니다. 코드 조각과 함께 각 부분의 기능을 이해함으로써, 특정 요구 사항 및 문서 유형에 맞게 문서 처리 프로세스를 보다 효과적으로 조정할 수 있습니다.
### 🔧 공통 구성요소
#### `HierarchicalChunker` 및 `HybridChunker`
`HierarchicalChunker`는 문서를 계층적으로 청크로 나누는 역할을 하며, `HybridChunker`는 토큰 제한을 고려하여 섹션별 청크를 분할하고 병합하는 고급 청커입니다.
```python
class HierarchicalChunker(BaseChunker):
merge_list_items: bool = True
def chunk(self, dl_doc: DLDocument, **kwargs: Any) -> Iterator[BaseChunk]:
# 모든 아이템과 헤더 정보 수집
all_items = []
all_header_info = [] # 각 아이템의 헤더 정보
current_heading_by_level: dict[LevelNumber, str] = {}
# 모든 아이템 순회하며 헤더 정보 추적
for item, level in dl_doc.iterate_items(included_content_layers={ContentLayer.BODY, ContentLayer.FURNITURE}):
# 섹션 헤더 처리
if isinstance(item, SectionHeaderItem) or (
isinstance(item, TextItem) and
item.label in [DocItemLabel.SECTION_HEADER, DocItemLabel.TITLE]
):
header_level = (
item.level if isinstance(item, SectionHeaderItem)
else (0 if item.label == DocItemLabel.TITLE else 1)
)
current_heading_by_level[header_level] = item.text
# ... 헤더 처리 로직
# 모든 아이템을 하나의 청크로 반환 (HybridChunker에서 분할)
# headings는 None으로 설정하고, 헤더 정보는 별도로 관리
chunk = DocChunk(
text="", # 텍스트는 HybridChunker에서 생성
meta=DocMeta(
doc_items=all_items,
headings=None, # DocMeta의 원래 형식 유지
captions=None,
origin=dl_doc.origin,
),
)
# 청크에 두 가지 헤더 정보 모두 저장
chunk._header_info_list = all_header_info
yield chunk
class HybridChunker(BaseChunker):
def chunk(self, dl_doc: DoclingDocument, **kwargs: Any) -> Iterator[BaseChunk]:
"""문서를 청킹하여 반환
Args:
dl_doc: 청킹할 문서
Yields:
토큰 제한에 맞게 분할된 청크들
"""
doc_chunks = list(self._inner_chunker.chunk(dl_doc=dl_doc, **kwargs))
if not doc_chunks:
return iter([])
doc_chunk = doc_chunks[0] # HierarchicalChunker는 하나의 청크만 반환
final_chunks = self._split_document_by_tokens(doc_chunk, dl_doc)
return iter(final_chunks)
```
#### `GenOSVectorMetaBuilder` 및 `GenOSVectorMeta`
`GenOSVectorMetaBuilder`는 각 청크에 대한 상세 메타데이터 객체인 `GenOSVectorMeta`를 단계적으로 생성하는 역할을 합니다.
**`GenOSVectorMeta` (Pydantic 모델)**
먼저, 최종적으로 생성될 메타데이터의 구조를 정의하는 Pydantic 모델입니다.
Python
```python
class GenOSVectorMeta(BaseModel):
class Config:
extra = 'allow' # Pydantic v2에서는 extra='allow' 대신 model_config 사용 가능
text: str = None
n_char: int = None
n_word: int = None
n_line: int = None
e_page: int = None
i_page: int = None
i_chunk_on_page: int = None
n_chunk_of_page: int = None
i_chunk_on_doc: int = None
n_chunk_of_doc: int = None
n_page: int = None
reg_date: str = None
chunk_bboxes: str = None
media_files: str = None
title: str = None
created_date: int = None
```
**설명:**
* `BaseModel`을 상속받아 Pydantic 모델로 정의됩니다. 이는 데이터 유효성 검사 및 직렬화/역직렬화를 용이하게 합니다.
* `Config.extra = 'allow'`: 모델에 정의되지 않은 추가 필드가 입력 데이터에 존재하더라도 오류를 발생시키지 않고 허용합니다. (Pydantic V2에서는 `model_config = ConfigDict(extra='allow')` 형태로 사용)
* 각 필드는 청크의 메타데이터 항목을 나타냅니다.
* `text`: 청크의 텍스트 내용.
* `n_char`, `n_word`, `n_line`: 문자 수, 단어 수, 줄 수.
* `e_page`, `i_page`, `i_chunk_on_page`, `n_chunk_of_page`: 페이지 내에서의 청크 위치 정보.
* `i_chunk_on_doc`, `n_chunk_of_doc`: 문서 전체에서의 청크 위치 정보.
* `n_page`: 문서의 총 페이지 수.
* `reg_date`: 처리 등록 시간.
* `bboxes`: 페이지 내 해당 청크의 경계 상자 (JSON 문자열 형태).
* `chunk_bboxes`: 청크를 구성하는 각 `DocItem`의 상세 경계 상자 정보 리스트.
* `media_files`: 청크 내 포함된 미디어 파일(이미지) 정보 리스트.
* **고객사별 필드**: `title`, `created_date` 등은 고객사의 특정 요구사항에 따라 추가된 메타데이터 필드입니다.
**사용자 정의 포인트:**
* 고객사에서 필요한 추가적인 메타데이터 항목이 있다면, 이 `GenOSVectorMeta` 모델에 새로운 필드를 추가로 정의할 수 있습니다.
* 필드 타입을 보다 엄격하게 정의하거나 (예: `Optional[str]`), 기본값을 설정하거나, 유효성 검사 로직을 추가할 수 있습니다.
***
**`GenOSVectorMetaBuilder` 클래스 및 주요 메서드**
`GenOSVectorMeta` 객체를 생성하는 빌더 클래스입니다.
Python
```python
class GenOSVectorMetaBuilder:
def __init__(self):
"""빌더 초기화"""
self.text: Optional[str] = None
self.n_char: Optional[int] = None
# ... (다른 필드들도 초기화) ...
self.title: str = None
self.created_date: Optional[int] = None
def set_text(self, text: str) -> "GenOSVectorMetaBuilder":
"""텍스트와 관련된 데이터를 설정"""
self.text = text
self.n_char = len(text)
self.n_word = len(text.split())
self.n_line = len(text.splitlines())
return self
def set_page_info(
self, i_page: int, i_chunk_on_page: int, n_chunk_of_page: int
) -> "GenOSVectorMetaBuilder":
"""페이지 정보 설정"""
self.i_page = i_page
self.i_chunk_on_page = i_chunk_on_page
self.n_chunk_of_page = n_chunk_of_page
return self
def set_chunk_index(self, i_chunk_on_doc: int) -> "GenOSVectorMetaBuilder":
"""문서 전체의 청크 인덱스 설정"""
self.i_chunk_on_doc = i_chunk_on_doc
return self
def set_global_metadata(self, **global_metadata) -> "GenOSVectorMetaBuilder":
"""글로벌 메타데이터 병합"""
for key, value in global_metadata.items():
if hasattr(self, key): # 빌더 내에 해당 속성이 정의되어 있는지 확인
setattr(self, key, value)
return self
def set_chunk_bboxes(self, doc_items: list, document: DoclingDocument) -> "GenOSVectorMetaBuilder":
self.chunk_bboxes = []
for item in doc_items:
for prov in item.prov:
label = item.self_ref
type_ = item.label
size = document.pages.get(prov.page_no).size
page_no = prov.page_no
bbox = prov.bbox
bbox_data = {'l': bbox.l / size.width,
't': bbox.t / size.height,
'r': bbox.r / size.width,
'b': bbox.b / size.height,
'coord_origin': bbox.coord_origin.value}
chunk_bboxes.append({'page': page_no, 'bbox': bbox_data, 'type': type_, 'ref': label})
self.e_page = max([bbox['page'] for bbox in chunk_bboxes]) if chunk_bboxes else None
self.chunk_bboxes = json.dumps(chunk_bboxes)
return self
def set_media_files(self, doc_items: list) -> "GenOSVectorMetaBuilder":
temp_list = []
for item in doc_items:
if isinstance(item, PictureItem): # DocItem이 PictureItem인 경우
path = str(item.image.uri) # 이미지 파일 경로
name = path.rsplit("/", 1)[-1] # 파일 이름만 추출
temp_list.append({'name': name, 'type': 'image', 'ref': item.self_ref})
self.media_files = temp_list
return self
def build(self) -> GenOSVectorMeta:
"""설정된 데이터를 사용해 최종적으로 GenOSVectorMeta 객체 생성"""
return GenOSVectorMeta(
text=self.text,
n_char=self.n_char,
# ... (모든 필드를 GenOSVectorMeta 생성자에 전달) ...
title=self.title,
created_date=self.created_date,
)
```
**설명:**
* **`__init__`**: 빌더 내부의 모든 속성들을 초기화합니다. 이 속성들은 `GenOSVectorMeta`의 필드들과 대부분 일치합니다.
* **`set_text`**: 청크의 텍스트를 설정하고, 문자 수, 단어 수, 줄 수를 계산하여 내부 속성에 저장합니다.
* **`set_page_info`**: 페이지 번호, 페이지 내 청크 인덱스, 페이지 내 총 청크 수를 설정합니다.
* **`set_chunk_index`**: 문서 전체에서의 청크 인덱스를 설정합니다.
* **`set_global_metadata`**: `DocumentProcessor.compose_vectors`에서 전달받은 `global_metadata` 딕셔너리의 값들을 빌더의 해당 속성에 할당합니다. 빌더 내에 `global_metadata`의 키와 동일한 이름의 속성이 있어야 값이 할당됩니다.
* **`set_chunk_bboxes`**: 청크를 구성하는 모든 `DocItem`들의 상세한 경계 상자 정보를 추출하여 리스트로 저장합니다. 각 항목은 페이지 번호, 정규화된 좌표(0\~1 값), `DocItem`의 타입 및 참조 ID를 포함합니다. 정규화된 좌표는 페이지 크기에 상대적인 위치를 나타내므로, 다양한 크기의 페이지에서도 일관되게 위치를 표현할 수 있습니다.
* **`set_media_files`**: 청크 내에 `PictureItem`(이미지)이 포함되어 있다면, 해당 이미지의 파일 이름, 타입("image"), 참조 ID를 추출하여 리스트로 저장합니다.
* **`build`**: 지금까지 `set_...` 메서드들을 통해 빌더 내부에 축적된 모든 속성값들을 사용하여 최종적으로 `GenOSVectorMeta` Pydantic 모델 객체를 생성하고 반환합니다.
**사용자 정의 포인트:**
* `GenOSVectorMeta` 모델에 새로운 필드를 추가했다면, 이 빌더에도 해당 필드를 위한 내부 속성과 `set_...` 메서드를 추가해야 합니다.
* `build` 메서드에서 `GenOSVectorMeta` 객체를 생성할 때 새로 추가된 필드도 인자로 전달하도록 수정해야 합니다.
* 특정 필드값을 설정하기 전에 추가적인 가공 로직(예: 날짜 형식 변환, 특정 코드값 매핑 등)이 필요하다면 해당 `set_...` 메서드 내부에 구현할 수 있습니다.
***
### 📂 공통 전처리 흐름
#### `DocumentProcessor`
`DocumentProcessor` 클래스는 Genos 의 전처리기가 호출되는 관문입니다. 내부 구성을 보면, 문서를 로드, 변환, 분할하고 각 부분에 대한 메타데이터를 구성하는 핵심 요소입니다.
**`__init__` (초기화)**
`DocumentProcessor` 인스턴스가 생성될 때 호출되는 초기화 메서드입니다. 여기서 문서 처리 파이프라인의 주요 설정들이 정의됩니다.
Python
```python
class DocumentProcessor:
def __init__(self):
'''
initialize Document Converter
'''
ocr_options = PaddleOcrOptions(
force_full_page_ocr=False,
lang=['korean'],
text_score=0.3)
self.page_chunk_counts = defaultdict(int)
device = AcceleratorDevice.AUTO
num_threads = 8
accelerator_options = AcceleratorOptions(num_threads=num_threads, device=device)
pipe_line_options = PdfPipelineOptions()
pipe_line_options.generate_page_images = True
pipe_line_options.generate_picture_images = True
pipe_line_options.do_ocr = False
pipe_line_options.artifacts_path = Path("/models/")
pipe_line_options.do_table_structure = True
pipe_line_options.images_scale = 2
pipe_line_options.table_structure_options.do_cell_matching = True
pipe_line_options.table_structure_options.mode = TableFormerMode.ACCURATE
pipe_line_options.accelerator_options = accelerator_options
# Simple 파이프라인 옵션을 인스턴스 변수로 저장
self.simple_pipeline_options = PipelineOptions()
self.simple_pipeline_options.save_images = False
# ocr 파이프라인 옵션
self.ocr_pipe_line_options = PdfPipelineOptions()
self.ocr_pipe_line_options = self.pipe_line_options.model_copy(deep=True)
self.ocr_pipe_line_options.do_ocr = True
self.ocr_pipe_line_options.ocr_options = ocr_options.model_copy(deep=True)
self.ocr_pipe_line_options.ocr_options.force_full_page_ocr = True
# 기본 컨버터들 생성
self._create_converters()
# enrichment 옵션 설정
self.enrichment_options = DataEnrichmentOptions(
do_toc_enrichment=False,
extract_metadata=True,
toc_api_provider="custom",
toc_api_base_url="http://llmops-gateway-api-service:8080/serving/13/23/v1/chat/completions",
metadata_api_base_url="http://llmops-gateway-api-service:8080/serving/13/23/v1/chat/completions",
toc_api_key="9e32423947fd4a5da07a28962fe88487",
metadata_api_key="9e32423947fd4a5da07a28962fe88487",
toc_model="/model/snapshots/9eb2daaa8597bf192a8b0e73f848f3a102794df5",
metadata_model="/model/snapshots/9eb2daaa8597bf192a8b0e73f848f3a102794df5",
toc_temperature=0.0,
toc_top_p=0,
toc_seed=33,
toc_max_tokens=1000
)
```
**설명:**
* `PaddleOcrOptions`: OCR(광학 문자 인식) 수행과 관련된 옵션을 설정합니다.
* `force_full_page_ocr = False`: OCR을 무조건 수행할지 여부입니다.
* `lang = ["korean"]`: OCR 수행 시 인식할 언어를 설정합니다. (예: 한국어) 정확한 언어 설정은 OCR 성능에 중요합니다.
* `text_score=0.3`: OCR 수행후 text 결과의 점수가 `text_score` 보다 높은 text만 출력합니다. text 점수는 0.0 \~ 1.0 범위로 부여되며 높을 수록 신뢰가 높다는 의미를 갖습니다.
* `self.page_chunk_counts = defaultdict(int)`: 페이지별로 생성된 청크의 수를 저장하기 위한 딕셔너리입니다.
* `AcceleratorOptions`: CPU 스레드 수(`num_threads`), 사용할 장치(`device`, 예: CPU/GPU 자동 선택) 등 하드웨어 가속 옵션을 설정합니다.
* **`PdfPipelineOptions`**: PDF 처리 방식에 대한 상세 설정을 담당합니다. 문서 유형 및 요구사항에 따라 이 부분을 주로 커스터마이징하게 됩니다.
* `generate_page_images = True`: PDF 각 페이지를 이미지로 생성할지 여부입니다.
* `generate_picture_images = True`: PDF 내에 삽입된 그림들을 별도의 이미지 파일로 추출할지 여부입니다.
* `do_ocr = False`: OCR(광학 문자 인식) 수행 여부입니다. 스캔된 PDF와 같이 텍스트 정보가 없는 이미지성 PDF의 경우 `True`로 설정해야 합니다.
* `artifacts_path`: 내부적으로 사용하는 모델 또는 임시 파일 경로를 지정할 수 있습니다.
* `do_table_structure = True`: 테이블 구조 인식 기능 사용 여부입니다.
* `table_structure_options.mode = TableFormerMode.ACCURATE`: 테이블 인식 정확도 모드를 설정합니다. `ACCURATE`는 정확도를 우선하며, `FAST`는 속도를 우선합니다.
* **`ocr_pipe_line_options`**: PDF 내의 텍스트에 대한 OCR 수행을 위해서 사용되는 설정입니다. 기본적으로 `pipe_line_options` 옵션을 복사해서 적용하며, OCR 수행에 대한 옵션을 추가로 설정합니다.
* `do_ocr = True`: OCR(광학 문자 인식) 수행 여부입니다. 스캔된 PDF와 같이 텍스트 정보가 없는 이미지성 PDF의 경우 `True`로 설정해야 합니다.
* `force_full_page_ocr = True`: 무조건 OCR을 수행하는 설정입니다. PDF에 text 정보가 존재하더라도 무시하고 OCR 수행을 합니다.
* **`enrichment_options`**: 문서의 메타데이터를 보강하기 위한 설정입니다. 이 옵션을 통해 문서의 목차, 메타데이터 추출 등을 수행할 수 있습니다.
* `do_toc_enrichment = False`: 목차 보강 기능 사용 여부입니다.
* `extract_metadata = True`: 문서의 메타데이터를 추출할지 여부입니다. 작성일을 추출할 수 있습니다.
* `toc_api_provider = "custom"`: 목차 API 제공자 설정입니다.
* `toc_api_base_url = "http://llmops-gateway-api-service:8080/serving/13/23/v1/chat/completions"`: 목차 API 기본 URL입니다.
* `metadata_api_base_url = "http://llmops-gateway-api-service:8080/serving/13/23/v1/chat/completions"`: 메타데이터 API 기본 URL입니다.
* `toc_api_key = "9e32423947fd4a5da07a28962fe88487"`: 목차 API 키입니다.
* `metadata_api_key = "9e32423947fd4a5da07a28962fe88487"`: 메타데이터 API 키입니다.
* `toc_model = "/model/"`: 목차 모델 경로입니다.
* `metadata_model = "/model/"`: 메타데이터 모델 경로입니다.
* `toc_temperature = 0.0`: 목차 생성 시 온도 설정입니다.
* `toc_top_p = 0`: 목차 생성 시 top-p 설정입니다.
* `toc_seed = 33`: 목차 생성 시 시드 설정입니다.
* `toc_max_tokens = 1000`: 목차 생성 시 최대 토큰 수 설정입니다.
***
**`_create_converters`**
문서 변환에 사용할 변환기를 설정하는 함수입니다.
Python
```python
def _create_converters(self):
"""컨버터들을 생성하는 헬퍼 메서드"""
self.converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=self.pipe_line_options,
backend=DoclingParseV4DocumentBackend
),
}
)
self.second_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=self.pipe_line_options,
backend=PyPdfiumDocumentBackend
),
},
)
self.ocr_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=self.ocr_pipe_line_options,
backend=DoclingParseV4DocumentBackend
),
}
)
self.ocr_second_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=self.ocr_pipe_line_options,
backend=PyPdfiumDocumentBackend
),
},
)
```
**설명:**
* **`self.converter` (기본 변환기)**: PDF를 처리하는 Primary 문서 변환기입니다. 이 백엔드는 복잡한 레이아웃이나 테이블 구조 인식에 강점이 있습니다.
* **`self.second_converter` (보조 변환기)**: `PyPdfiumDocumentBackend`를 사용하는 보조 변환기입니다. 기본 변환기가 특정 PDF 처리 중 오류를 발생시킬 경우, 이 변환기를 통해 재시도하는 폴백(fallback) 메커니즘으로 사용됩니다. `PyPdfium`은 비교적 간단한 PDF나 특정 유형의 PDF 처리에 더 안정적일 수 있습니다.
* **`self.ocr_converter` 및 `self.ocr_second_converter`**: OCR이 필요한 문서(예: 스캔된 이미지 PDF)를 처리하기 위한 변환기들입니다. 이들은 각각 `DoclingParseV4DocumentBackend`와 `PyPdfiumDocumentBackend`를 사용하여 OCR 처리를 수행합니다. OCR이 필요한 경우, 이 변환기들이 사용됩니다.s
***
**`load_documents_with_docling`, `load_documents_with_docling_ocr` 및 `load_documents`**
문서를 실제 로드하고 파싱하는 부분입니다.
Python
```python
def load_documents_with_docling(self, file_path: str, **kwargs: dict) -> DoclingDocument:
# kwargs에서 save_images 값을 가져와서 옵션 업데이트
save_images = kwargs.get('save_images', True)
include_wmf = kwargs.get('include_wmf', False)
# save_images 옵션이 현재 설정과 다르면 컨버터 재생성
if (self.simple_pipeline_options.save_images != save_images or
getattr(self.simple_pipeline_options, 'include_wmf', False) != include_wmf):
self.simple_pipeline_options.save_images = save_images
self.simple_pipeline_options.include_wmf = include_wmf
self._create_converters()
try:
conv_result: ConversionResult = self.converter.convert(file_path, raises_on_error=True)
except Exception as e:
conv_result: ConversionResult = self.second_converter.convert(file_path, raises_on_error=True)
return conv_result.document
def load_documents_with_docling_ocr(self, file_path: str, **kwargs: dict) -> DoclingDocument:
# kwargs에서 save_images 값을 가져와서 옵션 업데이트
save_images = kwargs.get('save_images', True)
include_wmf = kwargs.get('include_wmf', False)
# save_images 옵션이 현재 설정과 다르면 컨버터 재생성
if (self.simple_pipeline_options.save_images != save_images or
getattr(self.simple_pipeline_options, 'include_wmf', False) != include_wmf):
self.simple_pipeline_options.save_images = save_images
self.simple_pipeline_options.include_wmf = include_wmf
self._create_converters()
try:
conv_result: ConversionResult = self.ocr_converter.convert(file_path, raises_on_error=True)
except Exception as e:
conv_result: ConversionResult = self.ocr_second_converter.convert(file_path, raises_on_error=True)
return conv_result.document
def load_documents(self, file_path: str, **kwargs: dict) -> DoclingDocument:
# ducling 방식으로 문서 로드
return self.load_documents_with_docling(file_path, **kwargs)
# return documents
```
**설명:**
* `load_documents_with_docling(self, file_path: str, **kwargs: dict) -> DoclingDocument`:
* 주어진 `file_path`로부터 문서를 로드하고 `DoclingDocument` 객체로 변환하여 반환합니다.
* 핵심 로직은 `try-except` 블록 안에 있습니다.
* 먼저 `self.converter` (기본 변환기: `DoclingParseV4DocumentBackend`)를 사용하여 문서 변환을 시도합니다.
* 만약 `Exception`이 발생하면 (즉, 기본 변환기가 실패하면), `self.second_converter` (보조 변환기: `PyPdfiumDocumentBackend`)를 사용하여 다시 변환을 시도합니다. 이는 문서 처리의 안정성을 높여줍니다.
* `raises_on_error=True`는 변환 중 오류 발생 시 예외를 발생시키도록 합니다.
* 성공적으로 변환된 `conv_result.document` (즉, `DoclingDocument` 객체)를 반환합니다.
* `load_documents_with_docling_ocr(self, file_path: str, **kwargs: dict) -> DoclingDocument`:
* 주어진 `file_path`로부터 OCR이 필요한 문서를 로드하고 `DoclingDocument` 객체로 변환하여 반환합니다.
* 핵심 로직은 `try-except` 블록 안에 있습니다.
* 먼저 `self.ocr_converter` (기본 OCR 변환기: `DoclingParseV4DocumentBackend`)를 사용하여 문서 변환을 시도합니다.
* 만약 `Exception`이 발생하면 (즉, 기본 OCR 변환기가 실패하면), `self.ocr_second_converter` (보조 OCR 변환기: `PyPdfiumDocumentBackend`)를 사용하여 다시 변환을 시도합니다. 이는 문서 처리의 안정성을 높여줍니다.s
* `load_documents(self, file_path: str, **kwargs: dict) -> DoclingDocument`:
* `load_documents_with_docling` 메서드를 호출하여 문서를 로드하는 공개 인터페이스 역할을 합니다.
* `**kwargs`를 통해 추가적인 파라미터를 내부 메서드로 전달할 수 있는 구조입니다. (현재,`kwargs`가 직접적으로 활용되지는 않고 있습니다.)
**사용자 정의 포인트:**
* 문서 로딩 전 특정 전처리 작업이 필요하거나, PDF 외 다른 포맷에 대해 별도의 로직을 적용하고 싶다면 이 부분을 확장할 수 있습니다.
* `kwargs`를 활용하여 `PdfPipelineOptions`의 일부 값을 동적으로 변경하는 로직을 추가할 수도 있습니다 (예: 특정 문서 유형에 따라 OCR 활성화).
***
**`split_documents`**
로드된 문서를 의미 있는 작은 단위(청크)로 분할합니다.
Python
```python
def split_documents(self, documents: DoclingDocument, **kwargs: dict) -> list[DocChunk]:
chunker: HybridChunker = HybridChunker(
max_tokens=1000,
merge_peers=True
)
chunks: List[DocChunk] = list(chunker.chunk(dl_doc=documents, **kwargs))
for chunk in chunks:
self.page_chunk_counts[chunk.meta.doc_items[0].prov[0].page_no] += 1
return chunks
```
**설명:**
* `chunker: HybridChunker = HybridChunker()`: 문서를 청크로 나누기 위해 `HybridChunker` 인스턴스를 생성합니다. `HybridChunker`는 내부적으로 계층적 구조(Hierarchical)와 의미론적 분할(Semantic, 주석 처리된 `semchunk` 의존성 부분에서 유추)을 결합하여 문서를 분할합니다.
* `max_tokens`는 각 청크의 최대 토큰 수를 제한합니다.
* `merge_peers`는 인접한 청크들을 병합할지 여부를 결정합니다.
* `chunks: List[DocChunk] = list(chunker.chunk(dl_doc=documents, **kwargs))`: `chunker`의 `chunk` 메서드를 호출하여 `DoclingDocument`를 `DocChunk` 객체들의 리스트로 변환합니다. `**kwargs`는 청킹 과정에 필요한 추가 옵션을 전달하는 데 사용될 수 있습니다 .
* `for chunk in chunks: self.page_chunk_counts[chunk.meta.doc_items[0].prov[0].page_no] += 1`: 각 청크가 어떤 페이지에서 왔는지 파악하여 `self.page_chunk_counts` 딕셔너리에 페이지별 청크 수를 기록합니다. 이는 추후 메타데이터 생성 시 활용됩니다. (`chunk.meta.doc_items[0].prov[0].page_no`는 청크를 구성하는 첫번째 문서 아이템의 첫번째 출처 정보에서 페이지 번호를 가져옵니다.)
**사용자 정의 포인트:**
* `HybridChunker`의 설정 (예: 최대 토큰 수 `max_tokens`, 병합 옵션 `merge_peers`)은 `HybridChunker` 클래스 정의 부분에서 수정할 수 있습니다.
***
**`parse_created_date`**
작성일 텍스트를 파싱하여 YYYYMMDD 형식의 정수로 변환합니다.
Python
```python
def parse_created_date(self, date_text: str) -> Optional[int]:
"""
작성일 텍스트를 파싱하여 YYYYMMDD 형식의 정수로 변환
Args:
date_text: 작성일 텍스트 (YYYY-MM 또는 YYYY-MM-DD 형식)
Returns:
YYYYMMDD 형식의 정수, 파싱 실패시 None
"""
if not date_text or not isinstance(date_text, str) or date_text == "None":
return 0
# 공백 제거 및 정리
date_text = date_text.strip()
# YYYY-MM-DD 형식 매칭
match_full = re.match(r'^(\d{4})-(\d{1,2})-(\d{1,2})$', date_text)
if match_full:
year, month, day = match_full.groups()
try:
# 유효한 날짜인지 검증
datetime(int(year), int(month), int(day))
return int(f"{year}{month.zfill(2)}{day.zfill(2)}")
except ValueError:
pass
# YYYY-MM 형식 매칭 (일자는 01로 설정)
match_month = re.match(r'^(\d{4})-(\d{1,2})$', date_text)
if match_month:
year, month = match_month.groups()
try:
# 유효한 월인지 검증
datetime(int(year), int(month), 1)
return int(f"{year}{month.zfill(2)}01")
except ValueError:
pass
# YYYY 형식 매칭 (월일은 0101로 설정)
match_year = re.match(r'^(\d{4})$', date_text)
if match_year:
year = match_year.group(1)
try:
datetime(int(year), 1, 1)
return int(f"{year}0101")
except ValueError:
pass
return 0
```
**설명:**
* `date_text`가 유효한 문자열인지 확인합니다. 비어있거나 "None"인 경우 0을 반환합니다.
* 공백을 제거하고 정리합니다.
* `YYYY-MM-DD` 형식과 `YYYY-MM` 형식, `YYYY` 형식에 대해 정규 표현식을 사용하여 매칭을 시도합니다.
* 각 형식에 대해 유효한 날짜인지 검증하고, YYYYMMDD 형식의 정수로 변환하여 반환합니다.
* 모든 매칭이 실패한 경우 0을 반환합니다.
* 작성일이 명확하지 않거나 잘못된 형식인 경우 0으로 처리하여 데이터 일관성을 유지합니다.
***
**`enrichment`**
문서에 대한 추가 정보를 생성하거나 기존 정보를 보강하는 과정을 수행합니다.
Python
```python
def enrichment(self, document: DoclingDocument, **kwargs: dict) -> DoclingDocument:
# 새로운 enriched result 받기
document = enrich_document(document, self.enrichment_options)
return document
```
**설명:**
* 문서에 대한 추가 정보를 생성하거나 기존 정보를 보강하는 과정을 수행합니다.
* `enrich_document` 함수를 호출하여 문서를 보강하고, 보강된 문서를 반환합니다.
* 문서 보강에 필요한 추가 옵션은 `self.enrichment_options`에서 가져옵니다.
**작성일 메타데이터 추출 프로세스 상세:**
### 1. 프롬프트 구성 방식
메타데이터 추출은 두 가지 프롬프트로 구성됩니다:
* **`metadata_system_prompt`**:
* 기본값:
```
You are a highly skilled document extraction assistant specializing in Korean financial documents.
Your task is to carefully analyze the given document and extract the creation date with high accuracy.
```
* 사용자 정의 가능: `enrichment_options.metadata_system_prompt`로 설정
* **`metadata_user_prompt`**:
* 기본값:
```
Follow these instructions precisely:
Here is the financial document to analyze:
{document_content}
Process:
1. Extract and list all date expressions (2024.05.10, 24.05.10, 2024년 5월 10일, 5.10(금), etc.)
2. Analyze the context, paying attention to:
- Dates with "작성일", "작성일자", "작성", "게재 확정일"
- Dates near "보고자료", "회의자료"
- Dates at the top or beginning of document
3. Apply selection criteria:
- Prioritize explicitly labeled creation dates
- Exclude "기준일", "통계일", "데이터 기준일"
- Consider "최종수정일" only if no creation date found
4. Normalize to YYYY-MM-DD format
5. Output within tags (or 없음 if not found)
```
* 문서 내용이 `{document_content}` 플레이스홀더에 삽입됨
* 사용자 정의 가능: `enrichment_options.metadata_user_prompt`로 설정
### 2. created\_date로 변환 과정
enrichment를 통해 추출된 날짜는 다음 과정을 거쳐 최종 메타데이터가 됩니다:
**Step 1: KeyValueItem으로 저장**
```python
# 추출된 메타데이터를 GraphCell 구조로 변환
graph_cells = [
GraphCell(label=GraphCellLabel.KEY, text="작성일"),
GraphCell(label=GraphCellLabel.VALUE, text="2024-05-10")
]
document.add_key_values(graph=GraphData(cells=graph_cells))
```
**Step 2: compose\_vectors에서 추출**
```python
# document.key_value_items[0].graph.cells[1]에서 날짜 텍스트 추출
if document.key_value_items:
date_text = document.key_value_items[0].graph.cells[1].text
created_date = self.parse_created_date(date_text)
```
**Step 3: 날짜 형식 정규화**
```python
def parse_created_date(self, date_text: str) -> Optional[int]:
# "2024-05-10" → 20240510 (YYYYMMDD 정수)
# "2024-05" → 20240501 (일자를 01로 설정)
# "2024" → 20240101 (월일을 0101로 설정)
match_full = re.match(r'^(\d{4})-(\d{1,2})-(\d{1,2})$', date_text)
if match_full:
year, month, day = match_full.groups()
return int(f"{year}{month.zfill(2)}{day.zfill(2)}")
```
**Step 4: 최종 메타데이터 구성**
```python
global_metadata = dict(
created_date=created_date, # 20240510 형식의 정수
title=title,
authors_team=authors_team,
authors_department=authors_department
)
# 각 청크의 메타데이터에 포함
vector = GenOSVectorMetaBuilder()
.set_global_metadata(**global_metadata)
.build()
```
**사용자 정의 포인트:**
* **커스텀 프롬프트**: 고객사별 문서 형식에 맞춰 `metadata_system_prompt`와 `metadata_user_prompt`를 정의하여 추출 정확도 향상
* **추가 메타데이터**: 작성일 외에도 작성자, 부서, 문서 카테고리 등 다양한 메타데이터를 추출하도록 프롬프트 확장 가능
* **날짜 형식 처리**: `parse_created_date` 함수를 수정하여 다양한 날짜 형식 지원 가능
***
**`compose_vectors`**
분할된 청크들에 대해 메타데이터를 생성하고 최종적인 벡터(딕셔너리 형태) 리스트를 구성합니다. 이 부분이 고객사별 요구사항을 반영하는 부분이며 매우 중요합니다.
Python
```python
async def compose_vectors(self, document: DoclingDocument, chunks: List[DocChunk], file_path: str, request: Request,
**kwargs: dict) -> \
list[dict]:
title = ""
created_date = 0
try:
if (document.key_value_items and
len(document.key_value_items) > 0 and
hasattr(document.key_value_items[0], 'graph') and
hasattr(document.key_value_items[0].graph, 'cells') and
len(document.key_value_items[0].graph.cells) > 1):
# 작성일 추출 (cells[1])
date_text = document.key_value_items[0].graph.cells[1].text
created_date = self.parse_created_date(date_text)
except (AttributeError, IndexError) as e:
pass
for item, _ in document.iterate_items():
if hasattr(item, 'label'):
if item.label == DocItemLabel.TITLE:
title = item.text.strip() if item.text else ""
break
global_metadata = dict(
n_chunk_of_doc=len(chunks),
n_page=document.num_pages(),
reg_date=datetime.now().isoformat(timespec='seconds') + 'Z',
created_date=created_date,
title=title
)
current_page = None
chunk_index_on_page = 0
vectors = []
upload_tasks = []
for chunk_idx, chunk in enumerate(chunks):
chunk_page = chunk.meta.doc_items[0].prov[0].page_no
content = self.safe_join(chunk.meta.headings) + chunk.text
if chunk_page != current_page:
current_page = chunk_page
chunk_index_on_page = 0
vector = (GenOSVectorMetaBuilder()
.set_text(content)
.set_page_info(chunk_page, chunk_index_on_page, self.page_chunk_counts[chunk_page])
.set_chunk_index(chunk_idx)
.set_global_metadata(**global_metadata)
.set_chunk_bboxes(chunk.meta.doc_items, document)
.set_media_files(chunk.meta.doc_items)
).build()
vectors.append(vector)
chunk_index_on_page += 1
file_list = self.get_media_files(chunk.meta.doc_items)
upload_tasks.append(asyncio.create_task(
upload_files(file_list, request=request)
))
if upload_tasks:
await asyncio.gather(*upload_tasks)
return vectors
```
**설명:**
**한국은행 기록물의 메타데이타 Mapping 예**
* **`global_metadata`**: 문서 전체에 공통적으로 적용될 메타데이터를 딕셔너리로 구성합니다.
* `n_chunk_of_doc=len(chunks)`: 문서 내 총 청크 수.
* `n_page=document.num_pages()`: 문서의 총 페이지 수.
* `reg_date`: 현재 시간을 ISO 형식의 문자열로 등록일로 사용합니다.
* **고객사별 필드**: `created_date`, `title` 등은 enrichment를 통해 값을 가져와 설정됩니다. **이 부분이 고객사 시스템과 연동하여 문서의 고유 메타정보를 주입하는 핵심 지점입니다.**
* 루프 (`for chunk_idx, chunk in enumerate(chunks):`): 각 청크를 순회하며 메타데이터를 생성합니다.
* `chunk_page = chunk.meta.doc_items[0].prov[0].page_no`: 현재 청크의 시작 페이지 번호를 가져옵니다.
* `content = self.safe_join(chunk.meta.headings) + chunk.text`: 청크의 제목(headings)들과 실제 텍스트(text)를 결합하여 청크의 전체 내용을 구성합니다. `safe_join`은 제목 리스트를 안전하게 문자열로 합치는 유틸리티 함수로 보입니다.
* **`GenOSVectorMetaBuilder()`**: `GenOSVectorMetaBuilder`를 사용하여 체이닝 방식으로 각 메타데이터 필드를 설정합니다 (상세 내용은 `GenOSVectorMetaBuilder` 섹션 참조).
* `.set_text(content)`: 청크 내용 설정.
* `.set_page_info(...)`: 페이지 관련 정보 설정.
* `.set_chunk_index(chunk_idx)`: 문서 내 청크 인덱스 설정.
* `.set_global_metadata(**global_metadata)`: 위에서 정의한 `global_metadata`를 전달.
* `.set_chunk_bboxes(...)`: 청크를 구성하는 세부 항목들의 경계 상자 정보 설정.
* `.set_media_files(...)`: 청크 내 이미지 파일 정보 설정.
* `.build()`: 설정된 정보들을 바탕으로 `GenOSVectorMeta` 객체를 생성합니다.
* `vectors.append(...)`: 생성된 `GenOSVectorMeta` Pydantic 모델 객체를 `vectors` 리스트에 추가합니다.
* 페이지 변경 감지 로직: `current_page`와 `chunk_index_on_page`를 사용하여 페이지가 바뀔 때마다 페이지 내 청크 인덱스를 0으로 초기화합니다.
**사용자 정의 포인트 (매우 중요):**
* **`global_metadata` 확장**: 고객사의 고유한 문서 속성들(예: 작성일, 문서제목 등)을 `global_metadata`에 추가하고, 최종 메타데이터에 포함시킬 수 있습니다.
* `content` 구성 방식 변경: 단순히 제목과 텍스트를 합치는 것 외에, 특정 순서로 재배열하거나 요약 정보를 추가하는 등의 로직을 구현할 수 있습니다.
***
**`check_glyph_text`, `check_glyphs`**
PDF파일에 GLYPH 항목이 있는지 확인하는 메서드입니다. GLYPH는 PDF인코딩이 깨진 경우에 나타나는 항목입니다. GLYPH 항목이 발견되면, 해당 페이지의 텍스트를 대체하기 위해서 OCR을 수행합니다.
Python
```python
def check_glyph_text(self, text: str, threshold: int = 1) -> bool:
"""텍스트에 GLYPH 항목이 있는지 확인하는 메서드"""
if not text:
return False
# GLYPH 항목이 있는지 정규식으로 확인
matches = re.findall(r'GLYPH\w*', text)
if len(matches) >= threshold:
return True
return False
def check_glyphs(self, document: DoclingDocument) -> bool:
"""문서에 글리프가 있는지 확인하는 메서드"""
for item, level in document.iterate_items():
if isinstance(item, TextItem) and hasattr(item, 'prov') and item.prov:
page_no = item.prov[0].page_no
# GLYPH 항목이 있는지 확인. 정규식사용
matches = re.findall(r'GLYPH\w*', item.text)
if len(matches) > 10:
return True
return False
```
**설명:**
* `check_glyph_text(self, text: str, threshold: int = 1) -> bool`:
* 주어진 텍스트에 "GLYPH" 항목이 포함되어 있는지 확인합니다.
* 정규 표현식을 사용하여 "GLYPH"로 시작하는 단어들을 찾아내고, 그 개수가 `threshold` 이상이면 `True`를 반환합니다.
* `check_glyphs(self, document: DoclingDocument) -> bool`:
* 주어진 문서에 "GLYPH" 항목이 포함되어 있는지 확인합니다.
* 문서 내 모든 텍스트 항목을 검사하여 "GLYPH"로 시작하는 단어가 10개 이상이면 `True`를 반환합니다.
***
**`ocr_all_table_cells`**
테이블의 모든 셀에 대해 GLYPH 항목이 있는 경우에만 OCR을 수행합니다. 테이블에서 비정상적으로 GLYPH 항목이 많이 발생하는 경우, 임베딩 토큰이 허용치를 넘어가는 경우가 발생할 수 있기 때문에 중요한 부분입니다.
Python
```python
def ocr_all_table_cells(self, document: DoclingDocument, pdf_path) -> List[Dict[str, Any]]:
"""
글리프 깨진 텍스트가 있는 테이블에 대해서만 OCR을 수행합니다.
Args:
document: DoclingDocument 객체
pdf_path: PDF 파일 경로
Returns:
OCR이 완료된 문서의 DoclingDocument 객체
"""
try:
import fitz
import grpc
import docling.models.ocr_pb2 as ocr_pb2
import docling.models.ocr_pb2_grpc as ocr_pb2_grpc
import itertools
grpc_server_count = self.ocr_pipe_line_options.ocr_options.grpc_server_count
PORTS = [50051 + i for i in range(grpc_server_count)]
channels = [grpc.insecure_channel(f"localhost:{p}") for p in PORTS]
stubs = [(ocr_pb2_grpc.OCRServiceStub(ch), p) for ch, p in zip(channels, PORTS)]
rr = itertools.cycle(stubs)
doc = fitz.open(pdf_path)
for table_idx, table_item in enumerate(document.tables):
if not table_item.data or not table_item.data.table_cells:
continue
b_ocr = False
for cell_idx, cell in enumerate(table_item.data.table_cells):
if self.check_glyph_text(cell.text, threshold=1):
b_ocr = True
break
if b_ocr is False:
# 글리프 깨진 텍스트가 없는 경우, OCR을 수행하지 않음
continue
for cell_idx, cell in enumerate(table_item.data.table_cells):
# # Provenance 정보에서 위치 정보 추출
if not table_item.prov:
continue
page_no = table_item.prov[0].page_no - 1
bbox = cell.bbox
page = doc.load_page(page_no)
# 셀의 바운딩 박스를 사용하여 이미지에서 해당 영역을 잘라냄
cell_bbox = fitz.Rect(
bbox.l, min(bbox.t, bbox.b),
bbox.r, max(bbox.t, bbox.b)
)
# bbox 높이 계산 (PDF 좌표계 단위)
bbox_height = cell_bbox.height
# 목표 픽셀 높이
target_height = 20
# zoom factor 계산
# (너무 작은 bbox일 경우 0으로 나누는 걸 방지)
zoom_factor = target_height / bbox_height if bbox_height > 0 else 1.0
zoom_factor = min(zoom_factor, 4.0) # 최대 확대 비율 제한
zoom_factor = max(zoom_factor, 1) # 최소 확대 비율 제한
# 페이지를 이미지로 렌더링
mat = fitz.Matrix(zoom_factor, zoom_factor)
pix = page.get_pixmap(matrix=mat, clip=cell_bbox)
img_data = pix.tobytes("png")
# gRPC 서버와 연결
# channel = grpc.insecure_channel('localhost:50051')
# stub = ocr_pb2_grpc.OCRServiceStub(channel)
# # OCR 요청: 이미지 데이터를 바이너리로 전송
# response = stub.PerformOCR(ocr_pb2.OCRRequest(image_data=img_data))
req = ocr_pb2.OCRRequest(image_data=img_data)
stub, port = next(rr) # 라운드 로빈 방식으로 스텁 선택
response = stub.PerformOCR(req)
cell.text = ""
for result in response.results:
if len(cell.text) > 0:
cell.text += " "
cell.text += result.text if result else ""
except grpc.RpcError as e:
pass
return document
```
**설명:**
* `grpc_server_count`: 사용할 OCR용 gRPC 서버의 수를 설정합니다. OCR용 gRPC 서버의 수는 기본값으로 4개가 사용됩니다.
* `PORTS`: 각 gRPC 서버의 포트 번호를 설정합니다. 50051부터 시작하여 `grpc_server_count`만큼 증가시킵니다.
* `channels`: 각 gRPC 서버와의 연결 채널을 생성합니다.
* `stubs`: 각 gRPC 서버에 대한 스텁을 생성합니다.
* `rr`: 라운드 로빈 방식으로 스텁을 선택하기 위한 반복자입니다.
* `for table_idx, table_item in enumerate(document.tables):`: 각 페이지에서 테이블을 찾아 해당 테이블의 셀을 순회하며 OCR을 수행합니다.
* `if not table_item.data or not table_item.data.table_cells:`: 테이블 아이템에 데이터가 없거나 셀 목록이 비어있는 경우, 해당 테이블은 건너뜁니다.
* `for cell_idx, cell in enumerate(table_item.data.table_cells):`: 각 테이블의 셀을 순회합니다.
* `if not table_item.prov:`: 테이블 아이템에 대한 Provenance 정보가 없는 경우, 해당 테이블은 건너뜁니다.
* `if self.check_glyph_text(cell.text, threshold=1):`: 셀의 텍스트가 GLYPH 항목이 아닌 경우, 해당 셀은 건너뜁니다.
* 각 셀의 영역을 이미지로 렌더링하고, gRPC 서버에 OCR 요청을 보냅니다.
***
**`__call__`**
`DocumentProcessor` 인스턴스를 GenOS 에서 호출할때의 진입점으로, 함수처럼 호출했을 때 실행되는 메인 로직입니다. 문서 처리의 전체 흐름을 담당합니다.
Python
```python
async def __call__(self, request: Request, file_path: str, **kwargs: dict):
document: DoclingDocument = self.load_documents(file_path, **kwargs)
if not check_document(document, self.enrichment_options) or self.check_glyphs(document):
# OCR이 필요하다고 판단되면 OCR 수행
document: DoclingDocument = self.load_documents_with_docling_ocr(file_path, **kwargs)
# 글리프 깨진 텍스트가 있는 테이블에 대해서만 OCR 수행 (청크토큰 8k이상 발생 방지)
document: DoclingDocument = self.ocr_all_table_cells(document, file_path)
output_path, output_file = os.path.split(file_path)
filename, _ = os.path.splitext(output_file)
artifacts_dir = Path(f"{output_path}/{filename}")
if artifacts_dir.is_absolute():
reference_path = None
else:
reference_path = artifacts_dir.parent
document = document._with_pictures_refs(image_dir=artifacts_dir, reference_path=reference_path)
document = self.enrichment(document, **kwargs)
has_text_items = False
for item, _ in document.iterate_items():
if (isinstance(item, (TextItem, ListItem, CodeItem, SectionHeaderItem)) and item.text and item.text.strip()) or (isinstance(item, TableItem) and item.data and len(item.data.table_cells) == 0):
has_text_items = True
break
if has_text_items:
# Extract Chunk from DoclingDocument
chunks: List[DocChunk] = self.split_documents(document, **kwargs)
else:
# text가 있는 item이 없을 때 document에 임의의 text item 추가
from docling_core.types.doc import ProvenanceItem
# 첫 번째 페이지의 기본 정보 사용 (1-based indexing)
page_no = 1
# ProvenanceItem 생성
prov = ProvenanceItem(
page_no=page_no,
bbox=BoundingBox(l=0, t=0, r=1, b=1), # 최소 bbox
charspan=(0, 1)
)
# document에 temp text item 추가
document.add_text(
label=DocItemLabel.TEXT,
text=".",
prov=prov
)
# split_documents 호출
chunks: List[DocChunk] = self.split_documents(document, **kwargs)
vectors = []
if len(chunks) >= 1:
vectors: list[dict] = self.compose_vectors(document, chunks, file_path, **kwargs)
else:
raise GenosServiceException(1, f"chunk length is 0")
return vectors
```
**설명:**
1. `document: DoclingDocument = self.load_documents(file_path, **kwargs)`: `load_documents` 메서드를 호출하여 입력된 `file_path`의 문서를 로드합니다. `**kwargs`는 사용자가 입력 UI 를 통해서 지정하거나, 혹은 수집기가 수집단에서 지정한 정보를 전달합니다.
2. `if not check_document(document, self.enrichment_options) or self.check_glyphs(document): ...`: 문서가 유효하지 않거나 GLYPH 항목이 포함된 경우, OCR 처리를 위해 `load_documents_with_docling_ocr` 메서드를 호출합니다.
3. `document: DoclingDocument = self.ocr_all_table_cells(document, file_path)`: 문서 내 모든 테이블 셀에 대해 OCR 처리를 수행합니다.
4. 아티팩트 경로 설정:
* `output_path, output_file = os.path.split(file_path)`: 입력 파일 경로에서 디렉토리 경로와 파일 이름을 분리합니다.
* `filename, _ = os.path.splitext(output_file)`: 파일 이름에서 확장자를 제외한 순수 파일명을 얻습니다.
* `artifacts_dir = Path(f"{output_path}/{filename}")`: 문서 처리 과정에서 생성되는 이미지 등의 아티팩트(중간 결과물)를 저장할 디렉토리 경로를 구성합니다. 예를 들어, `input/mydoc.pdf` 라면 `input/mydoc/` 와 같은 경로가 됩니다.
* `reference_path` 설정: `artifacts_dir`이 절대 경로인지 상대 경로인지에 따라 이미지 참조를 위한 기본 경로를 설정합니다.
5. `document = document._with_pictures_refs(image_dir=artifacts_dir, reference_path=reference_path)`:
* `DoclingDocument` 객체 내의 그림(PictureItem)들이 실제 파일로 저장될 위치(`image_dir`)와 참조 경로(`reference_path`)를 설정하여, 그림 객체가 실제 파일 경로를 참조하도록 업데이트합니다. `PdfPipelineOptions`에서 `generate_picture_images = True`로 설정된 경우, `docling` 라이브러리가 내부적으로 이 경로에 이미지들을 저장하고, 이 메서드를 통해 문서 객체 내의 참조를 업데이트합니다.
6. `document = self.enrichment(document, **kwargs)`: 문서 객체에 추가적인 정보를 주입합니다.
7. `for item, _ in document.items(): ...`: 문서 내의 모든 항목에 대해 필수 텍스트 항목이 존재하는지 확인합니다.
* 만약 텍스트 항목이 하나라도 존재하면 `has_text_items`를 `True`로 설정합니다.
8. `chunks: List[DocChunk] = self.split_documents(document, **kwargs)`: 업데이트된 `document` 객체를 `split_documents` 메서드에 전달하여 청크 리스트를 얻습니다.
* text가 있는 item이 없을 때 document에 임의의 text item 추가합니다.
9. `vectors = [] ...`:
* 만약 생성된 청크가 1개 이상이면 (`len(chunks) >= 1`), `compose_vectors` 메서드를 호출하여 최종 메타데이터 벡터 리스트를 생성합니다.
* 청크가 하나도 없으면 `GenosServiceException`을 발생시켜 오류 상황임을 알립니다.
10. `return vectors`: 생성된 벡터 리스트를 반환합니다.
**사용자 정의 포인트:**
* `**kwargs` 활용: `__call__` 메서드에 전달되는 `**kwargs`는 내부적으로 `load_documents`, `split_documents`, `compose_vectors`로 전파될 수 있으므로, 문서 처리 전 과정에 걸쳐 동적인 설정을 주입하는 통로로 활용될 수 있습니다. 예를 들어, API 요청으로부터 특정 파라미터를 받아 `kwargs`로 전달하고, 이 값을 기반으로 `PdfPipelineOptions`의 일부를 변경하거나 `compose_vectors`에서 특정 메타데이터를 추가/제외하는 등의 로직을 구현할 수 있습니다.
* 아티팩트 관리: `artifacts_dir` 생성 규칙이나 `reference_path` 설정 방식을 변경하여, 생성되는 중간 파일들의 저장 위치 및 참조 방식을 조직의 정책에 맞게 수정할 수 있습니다.
### ✨ 사용자 정의 포인트
* **메타 필드 확장**: `GenOSVectorMeta`와 `Builder` 클래스에 필드 추가
* **페이지 처리 로직 수정**: `set_page_info` 파라미터 조정
* **청크 분할 커스터마이징**: `HybridChunker` 파라미터 기준값 수정
* **문자열 변환**: `NaN`, `None` 등 값은 전처리 단계에서 빈 문자열 처리
### ✅ 유지보수 팁
* Pydantic `extra='allow'` 설정으로 필드 변경이 유연하게 허용됨
* Builder 패턴을 사용하여 필드 설정 오류를 방지하고 유지보수를 단순화
***
이와 같이 코드 조각과 함께 설명을 보면서 `DocumentProcessor`와 `GenOSVectorMetaBuilder`의 작동 방식과 사용자 정의 지점을 파악하시면, 요구사항에 맞게 전처리 파이프라인을 효과적으로 수정하고 확장하실 수 있을 것입니다.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://genos-docs.gitbook.io/default/v1.6.7-bok/undefined-1/settings/resource/preprocessor/intelligent.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.